Dieser Post setzt den neunten Teil fort. Die bisherigen Teile haben gezeigt wie Bausteinsicht das Architekturmodell für Menschen lesbar macht — im Editor, in Diagrammen, in Reports. Dieser Teil dreht das um: wie macht man das Modell für Maschinen lesbar, damit LLM-Assistenten wie Claude Code damit arbeiten können?
Das Problem: LLMs kennen deine Architektur nicht
Claude Code, GitHub Copilot und andere KI-Assistenten wissen nichts über das konkrete System, an dem du arbeitest. Sie müssen erraten: welche Services existieren, wie sie miteinander kommunizieren, welche Technologien erlaubt sind.
Bausteinsicht löst das: das Architekturmodell ist eine maschinenlesbare Quelle der Wahrheit.
Mit --format json liefern alle Befehle strukturierte Ausgabe — genau das, was ein LLM als Kontext braucht.
--format json: Maschinenlesbare Ausgabe
Fast alle Bausteinsicht-Befehle unterstützen --format json:
bausteinsicht export --format json # vollständiges Modell als JSON
bausteinsicht lint --format json # Constraint-Verstöße strukturiert
bausteinsicht validate --format json # Validierungsfehler strukturiert
bausteinsicht health --format json # Health-Score mit Details
bausteinsicht find auth --format json # Suchergebnisse strukturiert
bausteinsicht status --format json # Lifecycle-Status aller Elemente
bausteinsicht snapshot list --format json # Snapshot-Liste strukturiert
bausteinsicht snapshot diff <id> --format json # Diff strukturiert
bausteinsicht changelog --format json # Changelog strukturiertDer Unterschied zur Textausgabe: JSON ist deterministisch, enthält keine Leerzeichen-Formatierung und lässt sich zuverlässig parsen — von Skripten und von LLMs.
bausteinsicht find: Das Modell abfragen
find durchsucht alle Elemente, Beziehungen und Views nach einem Begriff.
Die Suche ist case-insensitiv, partiell (pay'' trifft payment-service'') und verwendet AND-Semantik bei mehreren Wörtern.
# Alle Elemente zum Thema "auth"
bausteinsicht find auth
# Nur Elemente (keine Relationships oder Views)
bausteinsicht find auth --type element
# Mehrere Suchbegriffe (AND)
bausteinsicht find payment service
# JSON-Ausgabe für LLM-Kontext
bausteinsicht find auth --format jsonJSON-Ausgabe:
{
"query": "auth",
"total": 3,
"results": [
{
"type": "element",
"id": "authservice",
"kind": "service",
"title": "Auth Service",
"technology": "Go",
"score": 95
},
{
"type": "element",
"id": "authservice.tokenstore",
"kind": "database",
"title": "Token Store",
"technology": "Redis",
"score": 72
},
{
"type": "relationship",
"id": "shop.frontend→authservice",
"from": "shop.frontend",
"to": "authservice",
"title": "authenticate",
"score": 60
}
]
}Ergebnisse sind nach Relevanz-Score sortiert — der LLM erhält automatisch die relevantesten Treffer zuerst.
bausteinsicht status: Lifecycle-Übersicht
status listet alle Elemente mit ihrem Lifecycle-Status (→ Teil 3).
# Alle Elemente mit Status
bausteinsicht status
# Nur Elemente in einem bestimmten Status
bausteinsicht status --filter proposed
# Als JSON
bausteinsicht status --format jsonJSON-Ausgabe:
{
"summary": {
"proposed": 2,
"design": 1,
"implementation": 3,
"deployed": 8,
"deprecated": 1,
"archived": 0,
"unset": 2
},
"elements": [
{
"id": "authservice",
"kind": "service",
"title": "Auth Service",
"status": "deployed"
},
{
"id": "paymentservice.v2",
"kind": "service",
"title": "Payment Service v2",
"status": "proposed"
}
]
}Das Summary gibt einem LLM sofort einen Überblick: 2 Elemente sind proposed, 8 sind deployed — ohne das gesamte Modell zu laden.
Claude Code als Architektur-Assistent
Mit diesen Werkzeugen lässt sich Claude Code direkt in den Architektur-Workflow einbinden.
Modell als Kontext bereitstellen
Die einfachste Integration: relevanten Modell-Ausschnitt vor einer Frage in den Kontext geben.
# Im Terminal — dann Claude Code starten
bausteinsicht export --format json > /tmp/architecture.json
# In Claude Code: Datei lesen und Frage stellen
# "Lies /tmp/architecture.json und erkläre mir die Abhängigkeiten des payment-service"Oder direkter mit find:
bausteinsicht find payment --format json | \
claude -p "Welche Elemente sind mit dem Payment-Service verknüpft und \
gibt es offensichtliche Probleme in dieser Abhängigkeitsstruktur?"Architekturmodell via CLAUDE.md einbinden
In CLAUDE.md (oder .claude/CLAUDE.md) lässt sich ein permanenter Architekturkontext definieren:
## Architekturmodell
Das aktuelle Architekturmodell abfragen:
- `bausteinsicht export --format json` — vollständiges Modell
- `bausteinsicht find <begriff> --format json` — gezielter Kontext
- `bausteinsicht status --format json` — welche Elemente gerade in Entwicklung sind
Vor Entscheidungen mit Architektur-Einfluss: erst `bausteinsicht find` nutzen,
um bestehende Elemente und deren Beziehungen zu prüfen.Claude Code liest diese Instruktionen automatisch — ab jetzt kennt der Assistent die Befehle und kann sie selbst ausführen.
Workflow: Neues Element hinzufügen mit KI-Unterstützung
Ein realistisches Beispiel: ein neues Element soll ins Modell aufgenommen werden.
# 1. Bestehende ähnliche Elemente finden
bausteinsicht find notification --format json
# 2. Aktuell in Entwicklung?
bausteinsicht status --filter implementation --format json
# 3. Constraints prüfen bevor man hinzufügt
bausteinsicht lint --format jsonClaude Code kann diese Befehle in Folge ausführen und dann einen konsistenten JSONC-Eintrag vorschlagen — mit dem richtigen kind, passender technology, und ohne Constraint-Verstöße einzuführen.
Workflow: Architecture Review vor dem PR
In .github/PULL_REQUEST_TEMPLATE.md oder als CLAUDE.md-Anweisung:
# Diff zur Zielbranch
bausteinsicht changelog --since origin/main --until HEAD --format json
# Neue Constraint-Verstöße?
bausteinsicht lint --format json
# Health-Änderung?
bausteinsicht health --format jsonClaude Code kann diesen Review automatisch in die PR-Beschreibung einbauen.
Grenzen und Risiken
LLMs halluzinieren Elemente
Ein LLM kann plausibel klingende Element-IDs, Technologie-Werte oder Beziehungen erfinden, die nicht im Modell existieren.
Immer bausteinsicht validate nach KI-generierten Änderungen am Modell laufen lassen. Validate prüft Referenzen — halluzinierte IDs werden erkannt. |
JSON-Kontext hat Grenzen
Große Modelle (export --format json) können den Kontext-Window eines LLMs übersteigen.
find und status sind genau dafür da: zielgerichtete Teilausschnitte statt dem Gesamtmodell.
Faustregel: LLMs als präzise Suchanfragen formulieren → find → Ergebnis als Kontext, nicht das komplette Modell dumpen.
Modell als Single Source of Truth — nicht der LLM
Der LLM kann Vorschläge machen, aber das Modell in architecture.jsonc ist die Wahrheit.
bausteinsicht sync ist der Kanal zwischen Modell und draw.io — nicht der LLM.
Der LLM unterstützt den Architekten, er ersetzt ihn nicht.
Veralteter Kontext
Ein LLM-Assistent, dem die JSON-Ausgabe von vor drei Sprints als Kontext übergeben wurde, arbeitet mit einer veralteten Architektur.
Immer bausteinsicht export oder find im selben Terminal-Session ausführen, nicht gecachte Snapshots verwenden.
Praktische Abkürzungen
Für häufige Abfragen lohnen sich Shell-Aliase:
# ~/.bashrc oder ~/.zshrc
# Schneller Architektur-Kontext für Claude
alias arch-ctx='bausteinsicht export --format json'
alias arch-find='bausteinsicht find --format json'
alias arch-status='bausteinsicht status --format json'
# Review-Paket für PR
alias arch-review='bausteinsicht changelog --since origin/main --format json && bausteinsicht lint --format json'Beispiel-Modell
Das Beispiel für diesen Teil (Modell mit mehreren abfragbaren Elementen für bausteinsicht find) liegt unter teil_10.jsonc.
So sieht das Ergebnis in draw.io aus (bausteinsicht sync):
Das draw.io-File dafür findest du hier: teil_10.drawio
Generierte PNG-Dateien via bausteinsicht export --image-format png:
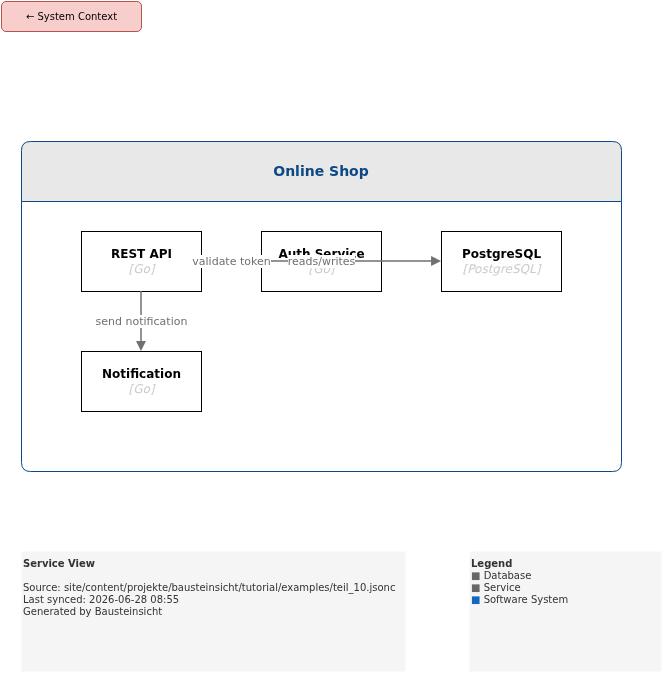
Generierte PlantUML-Diagramme via bausteinsicht export-diagram:
Was als nächstes kommt
Teil 11: ADR-Integration — Architecture Decision Records direkt im Modell verknüpfen
Teil 12: Overlay & Heatmap — Metriken auf Architekturdiagramme projizieren
Offizielle Dokumentation: User Manual · Tutorial auf doctoolchain.org